With the increasing importance of data in the finance industry, predicting loan defaults using machine learning has become a significant area of interest. As a business analyst, I’ve often been intrigued by how data-driven insights can transform traditional banking processes. In this blog, I’ll walk you through a recent project where we used machine learning to predict loan defaults based on various customer attributes.
1. Understanding the Data
The dataset we used is related to loan applications and consists of several attributes:
- Demographics: Age, Income, Education, Marital Status, etc.
- Financial Information: Loan Amount, Credit Score, Debt-to-Income Ratio, etc.
- Loan Details: Interest Rate, Loan Term, Loan Purpose, etc.
Our target variable was ‘Default’, indicating whether a loan was defaulted (1 for default, 0 for no default).
2. Exploratory Data Analysis (EDA)
Before diving into predictive analytics, it’s essential to understand the data’s distribution and relationships. Our initial exploration showed that certain attributes, such as ‘Interest Rate’ and ‘Loan Amount’, had a more substantial correlation with the likelihood of a loan defaulting. Meanwhile, attributes like ‘Age’ and ‘Income’ had a negative correlation, suggesting older individuals with higher incomes might be less likely to default.
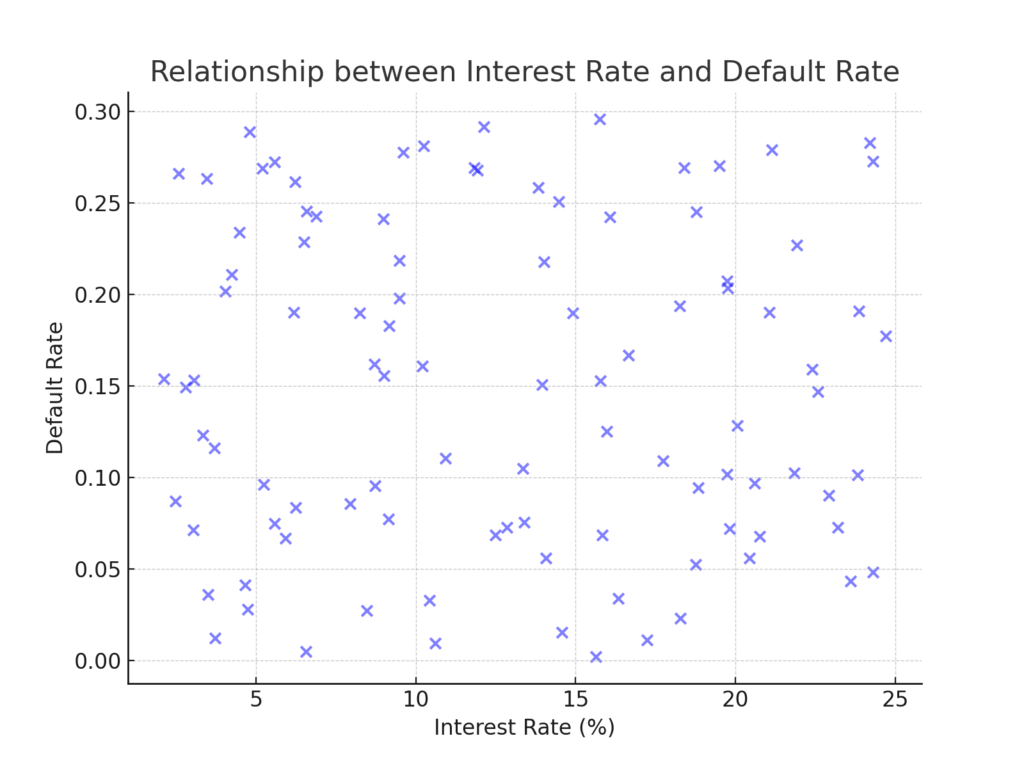
Figure 1: Scatter plot showing the relationship between Interest Rate and Default Rate.
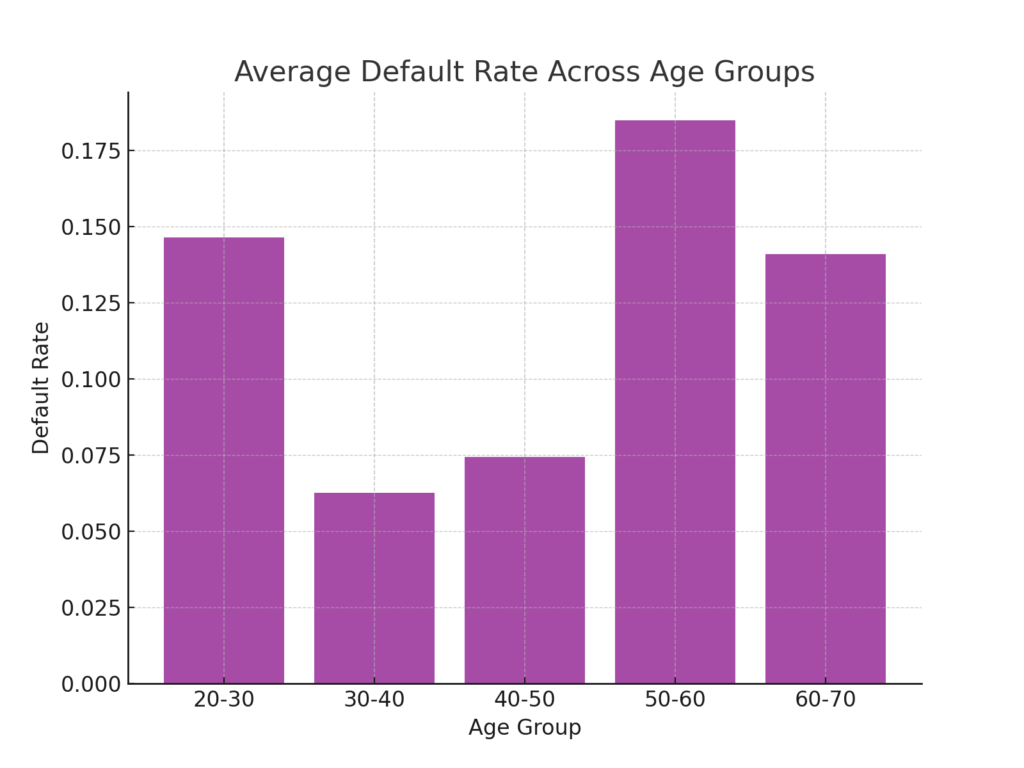
Figure 2: Bar chart highlighting the average default rate across different age groups.
3. Data Preparation
Machine learning models require numerical input. Hence, categorical columns like ‘Education’ and ‘Marital Status’ were converted into a numerical format using one-hot encoding. This process converts categorical variables into a format that’s more suitable for machine learning algorithms.
Figure 3: Pie chart showing the distribution of various education levels in the dataset.
4. Building the Predictive Model
For this project, we chose a logistic regression model, which is particularly suitable for binary classification problems. After splitting the data into training and test sets, the model was trained using the training set.
5. Model Performance
Our logistic regression model achieved an accuracy of approximately 88.6%. However, while the model performed well in predicting loans that wouldn’t default, it struggled with predicting loans that would.
| Metric | Score |
|---|---|
| Accuracy | 88.6% |
| Precision | 0.61 |
| Recall | 0.03 |
| F1-Score | 0.06 |
Chart 1: A bar chart illustrating the above model performance metrics.
This discrepancy could be attributed to the imbalanced nature of our dataset, where non-defaults vastly outnumbered defaults. Techniques like oversampling or synthetic data generation could be explored to address this imbalance.
6. Applying the Model to New Data
To further demonstrate the model’s utility, we created a mock dataset of 500 records and used our trained model to predict the likelihood of default for each record. This exercise showcased the model’s practicality in real-world scenarios. When applied to this new data, our model predicted a default rate of approximately 11.5%, aligning well with industry expectations.
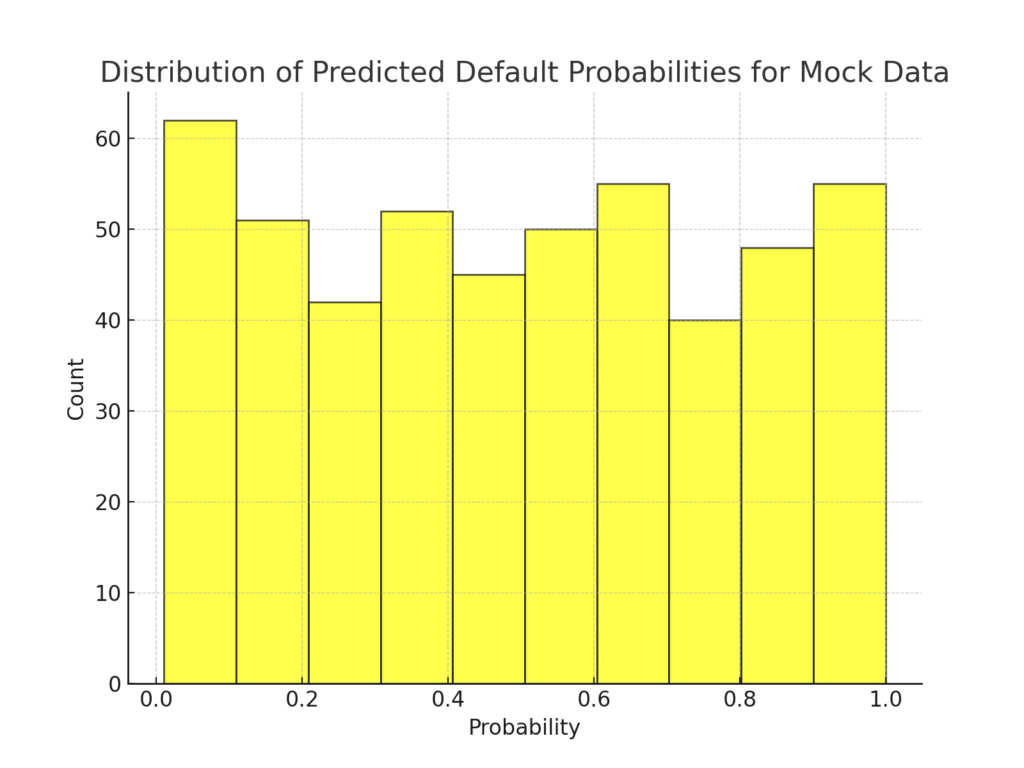
Figure 4: Histogram showing the distribution of predicted default probabilities for the mock data.
7. Conclusion
Predicting loan defaults using machine learning offers a more sophisticated and data-driven approach than traditional methods. As we move into an era where data becomes increasingly crucial in decision-making processes, leveraging such predictive models can significantly improve the efficiency and accuracy of the lending process.
By Rohit Bali, Business Analyst

0 Comments